查询慢
云笔记
two sum
ZYNQ
线性表
健身小程序
NISCTF
makefile
金融学
risc-v
Linux运维脚本
动态库
集成测试
深度卷积神经网络
初识SpringBoot
unicode、
lucene
推箱子游戏
分支优化
族谱
Text-to-Image
2024/4/13 20:20:51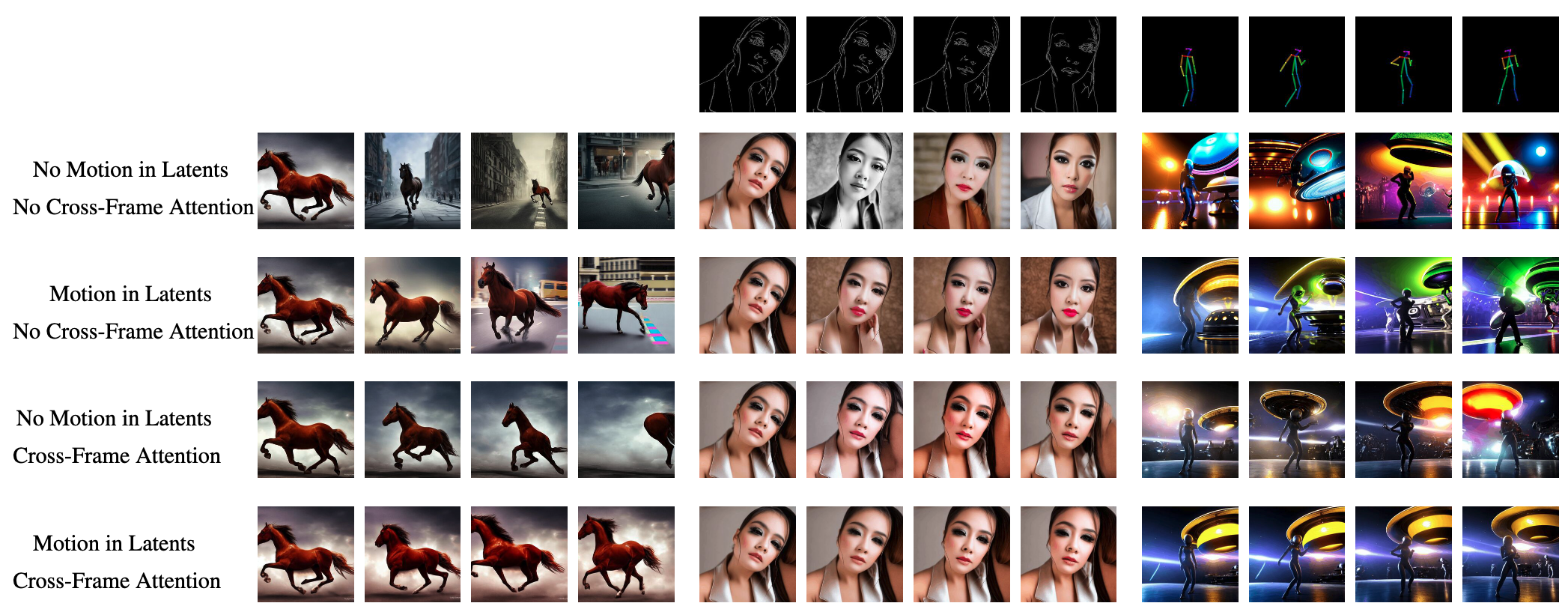
Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频生成器
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators Paper: https://arxiv.org/abs/2303.13439 Project: https://github.com/Picsart-AI-Research/Text2Video-Zero 原文链接:Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频…

【Stable Diffusion XL】huggingface diffusers 官方教程解读
文章目录 01 TutorialDeconstruct a basic pipelineDeconstruct the Stable Diffusion pipelineAutopipelineTrain a diffusion model 相关链接: GitHub: https://github.com/huggingface/diffusers 官方教程:https://huggingface.co/docs/di…
![[PMLR 2021] Zero-Shot Text-to-Image Generation:零样本文本到图像生成](https://img-blog.csdnimg.cn/img_convert/eae8c832d9fd3e9b696a3f02bb50b96a.png)
[PMLR 2021] Zero-Shot Text-to-Image Generation:零样本文本到图像生成
[PMLR 2021]Zero-Shot Text-to-Image Generation:零样本文本到图像生成 Fig 1. 原始图像(上)和离散VAE重建图像(下)的比较。编码器对空间分辨率进行8倍的下采样。虽然细节(例如,猫毛的纹理、店面上的文字和插图中的细线)有时会丢失或扭曲,但图…
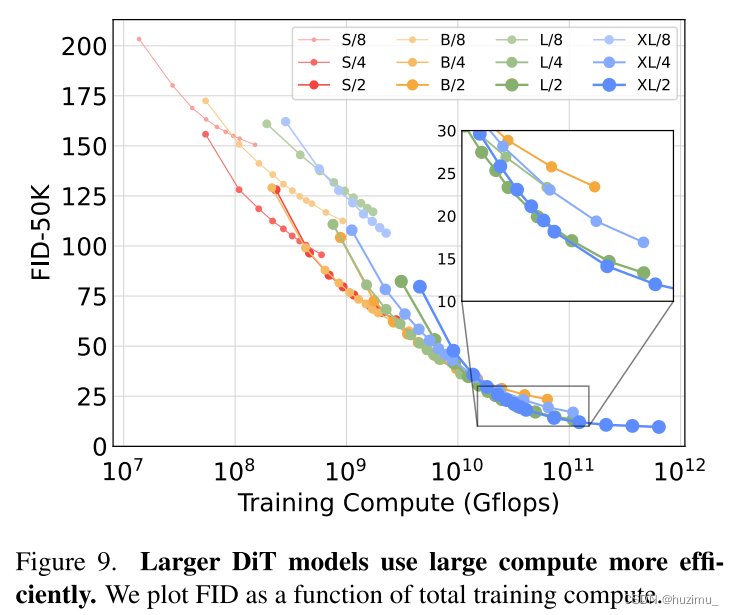
论文阅读:Scalable Diffusion Models with Transformers
Scalable Diffusion Models with Transformers
论文链接
介绍
传统的扩散模型基于一个U-Net骨架,这篇文章提出了一种新的扩散模型结构,将U-Net替换为一个transformer,并将这种结构称为Diffusion Transformers (DiTs)。他们还发现ÿ…